Projects

Transaction Labelling Tool
We had access to all client transactions, in the form of bank statements, but the transactions were not labelled; so we had to devise a plan to label the transactions. I developed a tool that utilised transaction embeddings (using an implementation of BERT) and clustering algorithms to label massive amounts of transactions on bank statements. Previously it would take quite a while to label bank statements that had hundreds of transactions, but with this tool, we could label similar transactions within seconds.
Read More
Automated Model Training Pipeline v1.0
In this project, I addressed a bottleneck in our data science workflow that was significantly limiting the data science team's productivity. Previously, our data scientists would manually launch an EC2 instance and set up a machine learning model for training. This was a time-consuming process - typically it took several hours for a data scientist to train a single model. Evaluating the results of this process usually led to a throughput of just one model per day per data scientist.To optimize this process, I developed an API using FastAPI with Python. The API is integrated with the Kubernetes API to automatically launch an EKS job for training a specified model pipeline. This innovative approach allowed us to initiate multiple model training runs via the API. The model pipeline to be trained could be easily specified through distinct configuration files, enabling us to train a variety of models simultaneously. As a result, we significantly increased our model training capacity and reduced the time spent per model, with the only limitation being the resource constraints of our Kubernetes cluster. We could launch at most 50 training runs on a test dataset. Through this project, we were able to greatly enhance our data science team's productivity and efficiency.
Read More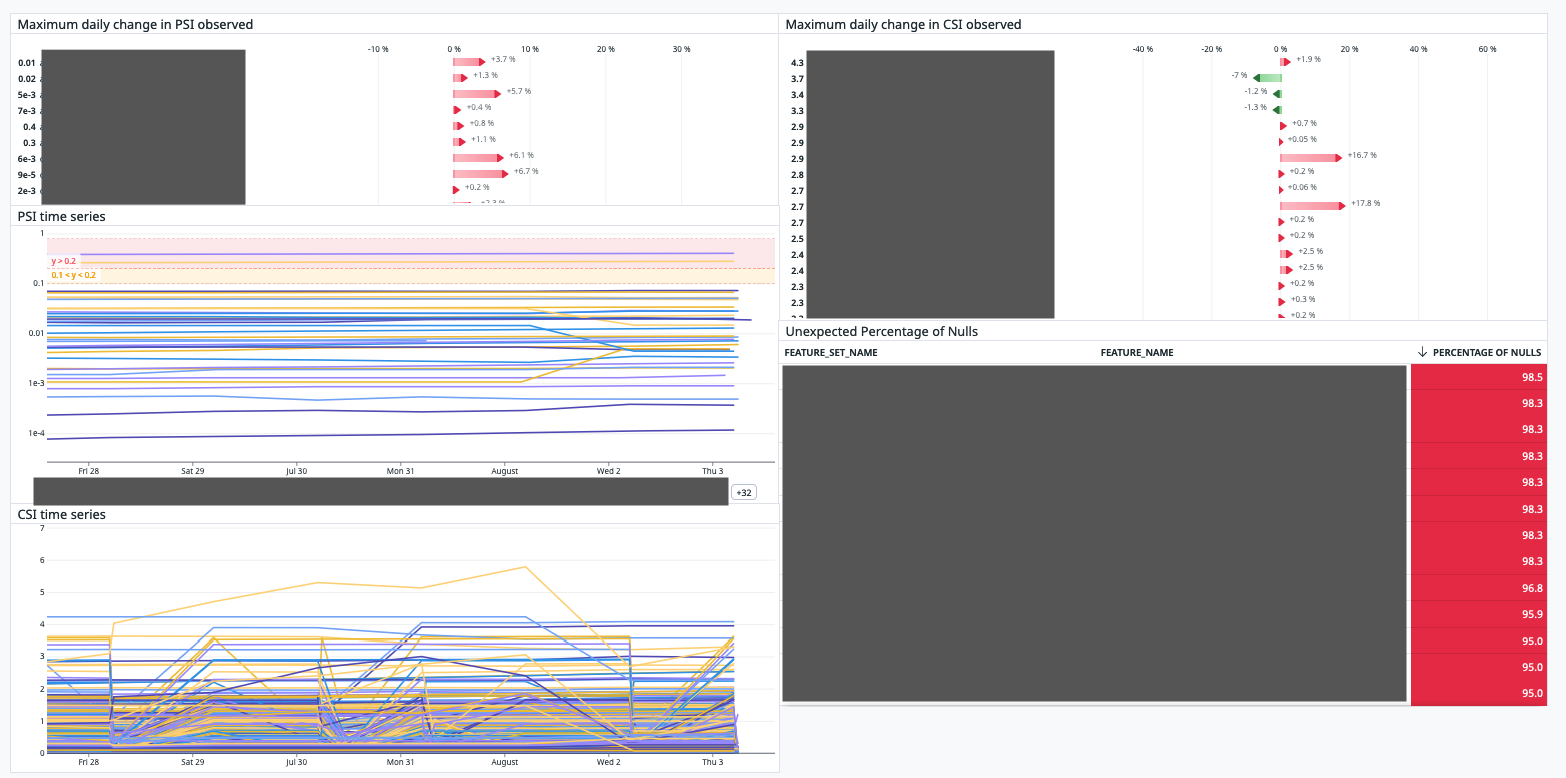
Model monitoring solution
In this project, I spearheaded the development of a model monitoring solution which drastically reduced data anomaly detection time from weeks to mere minutes. This was a significant enhancement for our operational efficiency. This solution automated the entire batch scoring process using Airflow, which orchestrated Amazon EKS Jobs for each segment of our system, including feature materialisation, model scoring, and monitoring subprocesses. To ensure comprehensive and reliable data monitoring, I utilized the Great Expectations library along with a custom API that I developed. This combination was used to validate datasets, as well as to compute the Population Stability Index (PSI) for model scores and the Characteristic Stability Index (CSI) for features with every daily run. In addition, the project involved creating an automated mechanism for our Airflow DAGs. Whenever a new model was deployed to our proprietary registry, a corresponding DAG was automatically created and scheduled to run the next day. Lastly, to provide a comprehensive view of our model's performance, all metrics were logged to a DataDog dashboard. This enabled us to monitor model performance consistently and make data-driven decisions for improvements.
Read More
Automated Model Deployment Pipeline v1.0
In this project, I significantly enhanced our model deployment process, which had been a time-consuming and labor-intensive task requiring about a week of work per engineer for each model deployment. Initially, the task involved establishing a formalized Model Life Cycle process. Subsequently, I designed and implemented an Automated Model Deployment pipeline that leveraged our team-developed, proprietary Artifact Registry. Our data scientists would train models and log them to MLFlow. Once logged, my automated process would retrieve the model and associated feature set artifacts from the underlying S3 location corresponding to the experiment on the MLFlow server. The artifacts would then be converted into packages compatible with our Artifact Registry. Following the conversion, the artifacts would be uploaded to the registry and initial tests would be conducted in the Development environment. Only after all checks, balances, and model validation steps were successfully passed, the model would then be deployed to the Staging environment. Here, our decision science team could validate the model scores. Upon successful verification of all tests and checks in the Staging environment, the model would be deployed to Production. Once in Production, a script on the Airflow server would identify and pick up the new model, decommission the old model, and automatically generate a DAG scheduled to run the next day. This newly streamlined process, which previously took up to a week, was now completed within hours. Furthermore, this process is parallelizable, allowing for the simultaneous deployment of multiple models. This represented a significant boost in efficiency and productivity for our team.
Read More
Automated Model Training Pipeline v2.0
In the original project scenario, our data scientists had to undertake a laborious and time-consuming multi-step process before they could commence actual model training. Firstly, they needed to create features from relatively large data sets for specific time windows. Our supportive engineering team helped to implement a process to manage this task utilizing EMR on EKS. Once the features were prepared, the data scientists then needed to train various models and select the optimal one for deployment. Upon experimentation, I noticed that certain model architectures consistently performed well with our data and seemed to generalize well across different scenarios, so I constructed some "champion" model architectures using deductive reasoning. Recognizing the tediousness and inefficiency of the existing process, I decided to introduce automation into the system to streamline it. Although there is no frontend at the time, the provided logs illustrate the operations of the service. The automated service triggers the data/feature creation process. Once the Metaflow DAG completes and the data has been prepared, the experiment is automatically initiated in MLFlow. This process triggers multiple model training runs, each with distinct model configurations based on the successful architectures I'd identified earlier. The result is a significantly accelerated process, with candidate models available for review and deployment within hours instead of days or weeks. This automation will greatly improve our productivity and efficiency in training and deploying machine learning models.
Read More
Protein Unfolding Pathways
The project is focused on the development of a novel way to approach protein folding pathways by considering a systematic geometric approach to unfolding a protein, and then folding it back up again using molecular dynamics principles, with the unfolding pathway as a "guide". This approach is inspired by the way in which origami is done, and is a novel approach to protein folding. The project is supervised by Prof. Hugh Patterton, Director of the Centre for Bioinformatics and Computational Biology at Stellenbosch University.
Read More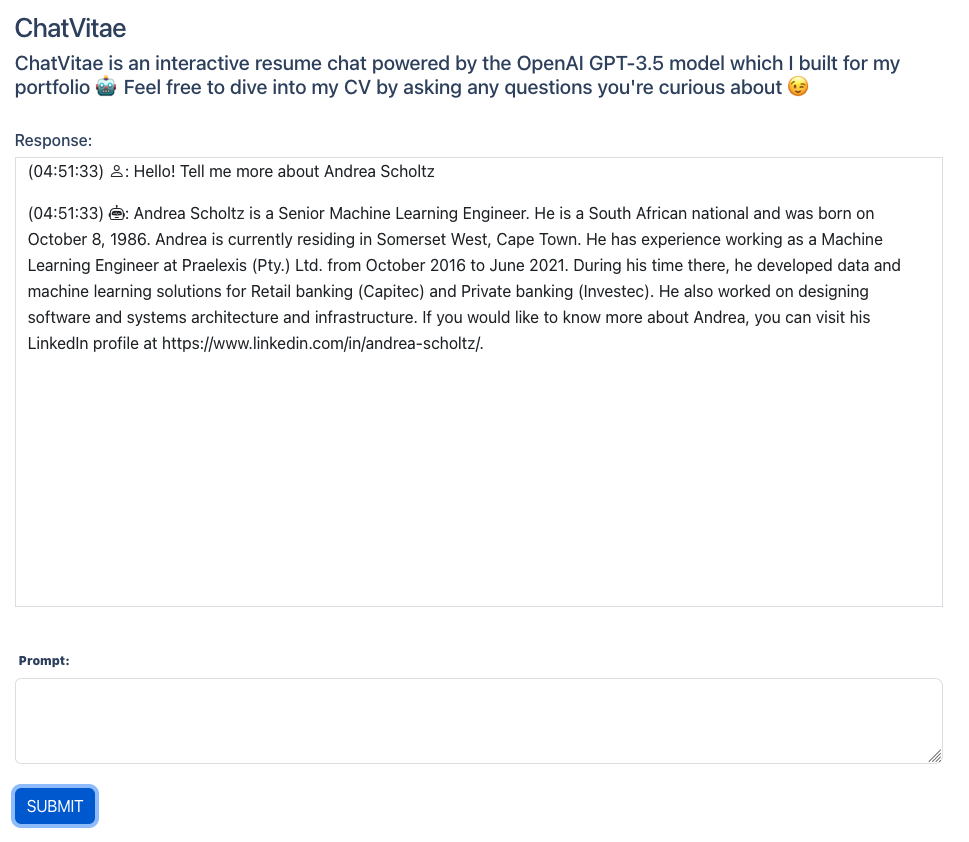
ChatVitae
I decided that I want to create a bespoke chatbot build on the GPT-3.5 API by OpenAI, fine-tuned to my CV, which is hosted on my website. I used LangChain and OpenAI APIs to interact with the GPT-3.5 API and fine-tune it with OpenAI's Embeddings API. The website is written in Django/Python and is hosted on AWS ElasticBeanstalk.
Read More